In this project, we developed a searchable index of patent classification codes that allows search by text and by code. We also extended this to allow users to explore the classification hierarchy. This blog entry page describes the demonstration web page.
Patent Classification pat-clas.t3as.org
For those unfamiliar with reading patents, we refer to The Lens and the tutorial, how to read a patent. Within patents, classification codes provide significant benefit in understanding and searching patents: patents with similar codes are likely to refer to similar content. From the British Library emphasis added
“The usefulness of patent classification as a means of searching for patents information is a by-product of its primary purpose as a tool for patent examiners. Using patent classification as part of a search to identify patents in a particular field can help the non-expert searcher to focus and refine his search and produce a useful set of references… However, it is a massive and complex tool designed for an expert user group and when it is used by anyone outside that user group it should be applied with care.”
For the non-expert, classification codes are difficult to use. For example, a patent for locomotive on the Lens, has two IPC classification codes associated with it: B61C17/04 and B61D27/00. What do these codes mean?
Entry point: web page
The text analytics service for this project is hosted at pat-clas.t3as.org and has a public Github repository for all code. The web page provides an open html file, that accesses the service API’s and presents a simple interface for text- or code- based search of CPC, IPC, and USPTO classification codes.
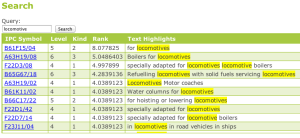
Free text search
The first field of the web page allows users to enter free text, and return classification codes. Following our example, let’s choose IPC, and enter “locomotive”. The search returns all IPC codes that contain “locomotive” in their text. The list is sorted based on relevance (rank), with all relevant search terms highlighted in the codes. The search returns at most the top 50 items.
The next field allows the user to find the context of a given code. Let’s try B61C17/04:

Code context
The context is build up of the the parent codes in the classification hierarchy, with their associated text stubs. Explore can also be used to view the hierarchy of the classification system – for example to find siblings of the code B61C17/04.

Classification hierarchy for Locomotive
The screen flow below outlines how to use the web page.
Under the hood: How it works
All the code is available on Public GitHub. If you are interested in developing applications that use this code, you should read the README on GitHub.
- CPC/IPC/USPTO codes are converted to list of string descriptions
- one for the code itself and
- one for each ancestor in the hierarchy.
This is a very simple database app with XML processing to populate the database.
- Given a text query, find CPC/IPC/USPTO codes that have descriptions matching the query. A very simple Lucene search app.
We’ll post more details soon.
The fine print
- The service is hosted on Amazon Web Services, with uptime on a best-effort basis and no redundancy.
- If requested, we may upgrade the hosting to production grade with hardware redundancy.
- The web page/user interface is designed as a demonstration of the underlying web services, and is not intended to be a user interface designed for any particular use case
This combines work from Neil Bacon, Gabriela Ferraro and Mats Henrikson



